
Jak działa Googlebot
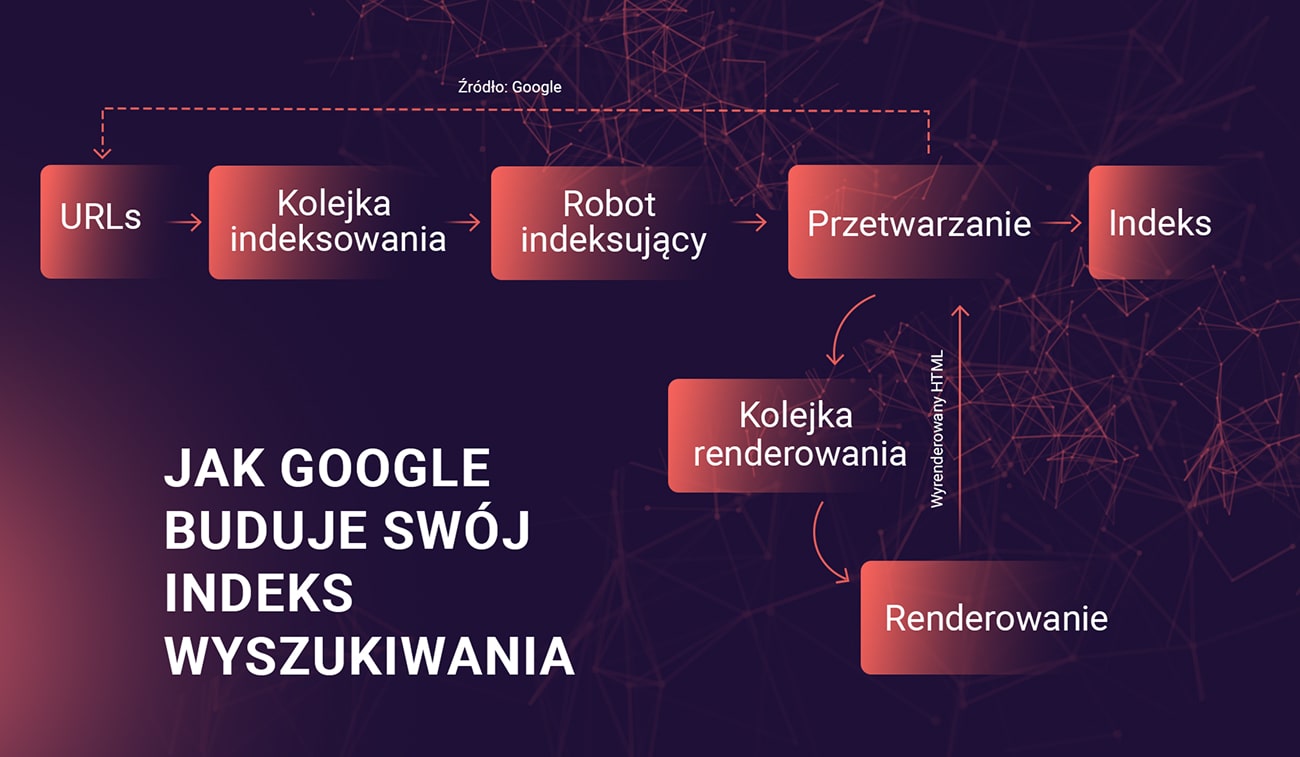
Robot indeksujący, znany także jako crawler lub spider, teoretycznie ma za zadanie odgrywać rolę człowieka przeszukującego internet w poszukiwaniu nowych stron. Przy okazji odwiedza on także wcześniejsze adresy w poszukiwaniu zmian czy aktualizacji. Cały workflow Googlebota jest znany – każdy z kroków, jaki podejmuje, jest częścią większego, algorytmicznego procesu indeksowania.
Odkrywanie stron
Wirtualny pracownik Google rozpoczyna swoją zmianę od przeanalizowania listy adresów URL, które są mu już znane. Tworzy on ją na podstawie witryn odwiedzonych w przeszłości czy map (sitemap) zgłoszonych przez właścicieli stron. Sprawdza on nowe linki, które odkrył w zeskanowanych stronach i adresy przesłane ręcznie do Google Search Console. Podczas skanowania witryn, robot identyfikuje i dodaje do kolejki kolejne odsyłacze do kontroli (dlatego też strony z dobrą strukturą linkowania wewnętrznego i dużą liczbą odsyłaczy zwrotnych są skuteczniej indeksowanie).
Pobieranie treści i renderowanie strony
Po odnalezieniu adresu URL, stworzony przez Google bot pobiera jego zawartość (kod HTML, pliki CSS, skrypty oraz multimedia). W przypadku nowoczesnych stron, gdzie wiele treści nie jest dostępnych od razu, a ich działanie wymaga wykonania poleceń JavaScript, robot musi dodatkowo wyrenderować stronę, podobnie jak robi to użytkownik, korzystając z przeglądarki. Pozwala mu to zobaczyć faktyczny wygląd strony, co szczególnie przydaje się, gdy części witryny oparte są na frameworkach typu react.js, angular.js czy vue.js. Niektóre serwisy używające intensywnie JavaScriptu mogą mieć problem z poprawnym indeksowaniem, w sytuacji gdy Googlebot nie da rady uruchomić poleceń poprawnie. W takich przypadkach warto zastosować pre-rendering, który dostarcza komputerowi gotową wersję.
Indeksowanie treści
Po przeanalizowaniu treści strony, robot decyduje, czy dodać ją do indeksu Google. Jeśli treść zawiera wartościowe informacje, jest unikalna i nie została zablokowana przez właściciela strony (o tym później), zostanie dodana do bazy danych. Google crawler może jednak wykryć duplikaty lub rozpoznać witrynę jako niskojakościową – w tym wypadku zostanie ona zignorowana lub zindeksowana w ograniczony sposób. Bot pod uwagę bierze przede wszystkim:
- Tytuł strony (<title>).
- Nagłówki (<h1>, <h2>, <h3>).
- Treść strony (słowa kluczowe i ich kontekst).
- Obrazy i ich opisy (alt).
- Strukturę linkowania wewnętrznego i zewnętrznego.
Nie wszystkie strony są indeksowane w całości – Google może pominąć niektóre elementy strony, jeśli uzna je za nieistotne dla wyników wyszukiwania.
 Spider nie odwiedza wszystkich serwisów w równym stopniu. Algorytm wyszukiwarki Google przydziela tzw. budżet indeksowania (crawl budget), który określa, ile podstron z danej witryny zostanie przeskanowanych w określonym czasie. Adresy www o wysokiej wartości i częstych aktualizacjach (np. duże portale informacyjne) są odwiedzane częściej niż małe, o niskiej aktywności.
Spider nie odwiedza wszystkich serwisów w równym stopniu. Algorytm wyszukiwarki Google przydziela tzw. budżet indeksowania (crawl budget), który określa, ile podstron z danej witryny zostanie przeskanowanych w określonym czasie. Adresy www o wysokiej wartości i częstych aktualizacjach (np. duże portale informacyjne) są odwiedzane częściej niż małe, o niskiej aktywności.
Rodzaje Googlebotów
Wszystkie boty pełnią podobną funkcję – pomagają budować indeks wyszukiwarki – ich zdania jednak mogą różnić się w zależności od rodzaju treści, które skanują. Z powodu licznych zmian i aktualizacji, najważniejszym “pracownikiem” stał się Googlebot na smartfona. Nie oznacza to jednak, że to jeden, jedyny robot, który odpowiedzialny jest za indeksację.
Smartfony przede wszystkim
Do 2020 roku, do skanowania stron wykorzystywany był Googlebot Desktop, który analizował strony tak, jakby odwiedzał je użytkownik korzystający z komputera stacjonarnego. Jednak od momentu wprowadzenia Mobile-First Indexing, Google wartościuje i indeksuje strony wyłącznie na podstawie wersji mobilnych. Jeśli witryna nie została dostosowana do urządzeń przenośnych, nie znajdzie się ona w indeksie najpopularniejszej wyszukiwarki. Nawet jeśli jest częściowo dostępna na telefonach czy tabletach, ale nie w wersji w pełni zoptymalizowanej, Google może obniżyć jej ranking. To oznacza utracony ruch organiczny i spadek widoczności w wynikach wyszukiwania.
Google Search Console oferuje test wersji mobilnej, by właściciel strony mógł sprawdzić, czy robot będzie w stanie przeanalizować witrynę tak, jak należy. Służy do tego narzędzie „Testowanie adresu URL”. Jeśli w raporcie pojawi się komunikat „Strona nie jest przyjazna dla urządzeń mobilnych”, oznacza to, że Google może jej poprawnie nie indeksować. W innym przypadku, w logach serwera powinien pojawić się następujący user-agent:
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Inne rodzaje Googlebota
Oprócz wersji smartfonowej i desktopowej, firma używa także robotów do indeksowania obrazów, treści video, wiadomości (przeznaczonych do Google News), a także sprawdza strony pod kątem zgodności z zasadami systemu Ads.
| Rodzaj Googlebota | Opis |
| Googlebot Smartphone | Główny robot indeksujący, ocenia strony na podstawie ich wersji mobilnej. |
| Googlebot Desktop | Dawniej główny robot indeksujący, skanował strony w wersji na komputery stacjonarne. Obecnie używany sporadycznie. |
| Googlebot-Image | Indeksuje obrazy na stronach internetowych, analizuje atrybuty alt, tytuły obrazów i kontekst. |
| Googlebot-Video | Indeksuje treści wideo, analizuje pliki multimedialne oraz metadane wideo. |
| Googlebot-News | Indeksuje treści wiadomości dla Google News. Strony muszą spełniać określone wymagania. |
| AdsBot-Google | Analizuje strony pod kątem zgodności z zasadami Google Ads, wpływa na ranking reklam. |
Czy mogę zablokować dostęp Google crawlera do strony?
Google robot, co do zasady, zaprogramowany jest tak, by indeksować jak najwięcej treści dostępnych w internecie. Jednak właściciele stron niekiedy mogą chcieć ograniczyć jego dostęp do niektórych sekcji swoich witryn lub całkowicie uniemożliwić mu wpisanie jej do rejestru. Opcja ta sprawdza się idealnie w przypadku, gdy w serwisie zawarte są duże zasoby nieprzeznaczone do indeksowania oraz gdy właściciel chce zaoszczędzić crawl budget na ważniejsze podstrony.
Sposobów zarządzania dostępem dla Googlebota jest wiele, choć najpopularniejszym z nich wydaje się ingerencja w robots.txt. To plik tekstowy umieszczany w głównym katalogu witryny zawierający instrukcje dla robotów indeksujących. Jego treść określa, które katalogi strony mogą być skanowane oraz jakie należy ominąć. Wpisując do instrukcji regułę:
User-agent: Googlebot
Disallow: /katalog/ (np. /blog/)
zapobiegamy skanowaniu przez Googlebota, ale, co ważne, nie uniemożliwiamy jej indeksowania. Jeśli na innej podstronie znajdują się linki prowadzące do zablokowanych części, Google nadal może dodać te adresy do bazy danych, choć nie będzie znał ich zawartości. Jeśli zaś w interesie strony jest uniemożliwienie robotom indeksowania strony, ale pozwolenie im na jej skanowanie, należy użyć odpowiednich meta tagów w sekcji <head> strony HTML:
<meta name="robots" content="noindex, nofollow">
Znaczenie wartości:
- noindex – Googlebot nie doda strony do wyników wyszukiwania.
- nofollow – Googlebot nie będzie podążał za linkami znajdującymi się na stronie.
Warto pamiętać, że meta tag działa tylko wtedy, gdy robot indeksujący może zeskanować stronę. Jeśli plik robots.txt całkowicie blokuje dostęp, crawler Google może nigdy nie zobaczyć tego tagu, a strona nadal może pojawić się w indeksie.
Jak sprawdzić, czy ktoś nie podszywa się pod robota Google?
Niektóre boty spamerskie lub złośliwe skrypty wykorzystują identyfikator Googlebota, by uzyskać dostęp do stron i pozyskiwać informacje, które normalnie byłyby dla nich zablokowane. Jak więc upewnić się, że ruch faktycznie pochodzi ze sprawdzonego źródła, a nie fałszywego crawlera? Najpewniejszym sposobem jest sprawdzenie, kto odwiedza stronę. Google udostępnia adresy IP spiderów, których używa. Drugą metodą jest odwrotne wyszukiwanie DNS (reverse DNS lookup). Wystarczy sprawdzić, czy adres IP rzekomego Googlebota zwraca nazwę hosta w domenie googlebot.com lub google.com. Jeśli wyniki nie pasują do oficjalnych danych, mamy do czynienia z fałszywym botem. Dodatkowym sposobem jest monitorowanie aktywności robota w Google Search Console, gdzie można znaleźć raporty na temat liczby odwiedzin i statystyk indeksowania. Jeśli podejrzane żądania nie pokrywają się z aktywnością Googlebota w GSC, warto je zweryfikować.
Cyfrowa biblioteka
Googlebot to bez wątpienia jeden z najbardziej wpływowych „niewidzialnych” użytkowników internetu. To od niego zależy, które treści zostaną odkryte, zapamiętane i udostępnione milionom konsumentów na całym świecie. Cyfrowy bibliotekarz potrafi być surowy, lecz także sprawiedliwy. Docenia jakość, nie lubi chaosu i omija szerokim łukiem treści niskiej jakości. Nie jest jednak nieomylny – może pominąć wartościowe informacje lub napotkać techniczne bariery. Dbanie o przejrzystość, wartość i dostępność treści to dziś duża część dobrego SEO, która ma realny wpływ na to, gdzie w wynikach wyszukiwania znajdzie się nasza strona.





