
Google jest najczęściej używaną wyszukiwarką internetową na świecie, więc jej roboty także należą do najbardziej zapracowanych. Proces skanowania sieci to niełatwe zadanie. Ważna jest dokładność, ale również czas. Internauta chce bowiem otrzymać satysfakcjonujące odpowiedzi na zadane pytania możliwie szybko. Odpowiadają za to właśnie roboty Google. Ich pracę może w skuteczny sposób przyspieszyć za pomocą pliku o nazwie robots.txt. Jest on jednym ze standardów i mechanizmów Robots Exclusion Protocol (REP), a więc protokołu wykluczania robotów.
Spis treści
- Robots.txt – co to za plik?
- Gdzie znajduje się plik robots.txt?
- Do czego służy plik robots.txt?
- Jak działa robots.txt w praktyce?
- Dlaczego stosowanie robots.txt jest ważne?
- Robots.txt a działania SEO
- Zawartość pliku robots.txt
- Robots.txt – przykładowe reguły z przeznaczeniem dla algorytmów wyszukiwarek
- Jak stworzyć plik tekstowy robots?
- Testowanie pliku robots.txt i prawidłowości jego działani
- Najczęściej występujące błędy i problemy podczas tworzenia pliku robots.txt
- Wskazówki, zalecenia i uwagi dla użytkowników
- Podsumowanie
- FAQ – najczęstsze pytania i wątpliwości dotyczące pliku robots.txt
Robots.txt – co to za plik?
Aby dowiedzieć się, czym jest plik robots.txt, w pierwszej kolejności należy spojrzeć na jego rozszerzenie. To dodatkowe symbole liczbowe lub tekstowe umieszczone po kropce na końcu nazwy. W tym przypadku rozszerzeniem będzie zatem „txt”. Wynika z tego, że robots.txt jest zwykłym plikiem tekstowym. Pozostaje przy tym standardowy, prosty w budowie, nieduży i publicznie dostępny. Rozszerzenie determinuje również program, który powinien służyć do obsługi konkretnego elementu. W przypadku plików z rozszerzeniem „txt” wskazane są edytory tekstu. W najpopularniejszym systemie Microsoft Windows będzie to program Notepad.
Uwaga – zwróć uwagę na standard kodowania. Zaawansowane edytory tekstu mogą dodać nieoczekiwane znaki, takie jak cudzysłowy drukarskie, problematyczne dla robotów Google. Pamiętaj – plik robots.txt musi mieć kodowanie UTF-8.
Gdzie znajduje się plik robots.txt?
Każdy plik ma przypisane sobie miejsce. Ta zasada dotyczy również robots.txt. Plik ten umieszczany jest w głównym katalogu serwera strony internetowej (root directory). W związku z tym zawsze powinien być dostępny bezpośrednio pod adresem: Twojadomena.pl/robots.txt. Oczywiście nie każda strona internetowa go posiada. Wszystko zależy od potrzeb właściciela czy CMS-a – niektóre generują je automatycznie. Aby to sprawdzić, wystarczy do adresu URL własnej witryny w wyszukiwarce dopisać „/robots.txt”. W przypadku braku pliku w folderze głównym domeny pojawi się komunikat. Roboty Google informują wtedy o błędzie „404 Not Found”.
Do czego służy plik robots.txt?
Roboty wyszukiwarki internetowej mają swoje zasady postępowania w celu znalezienia odpowiedzi na pytania zadane przez internautów. Aby na nie wpłynąć i zarządzać ich ruchem, stosuje się właśnie robots.txt. To podstawowe narzędzie używane do komunikacji z robotami wyszukiwarki Google. Robots.txt moze wpływać na dalszy kierunek ich ruchu w obrębie danej strony ograniczając dostęp do niektórych zasobów – plików, folderów, skryptów czy podstron, jakie w kontekście konkretnego wyszukiwania są zbędne. Z założenia algorytmy powinny stosować się do stworzonych dla nich reguł i wytycznych. Niekiedy jednak bywa tak, że zawarte w pliku instrukcje traktowane są jako, nazwijmy to „informacje pomocnicze” a nie autorytarna lista nakazów i zakazów.
Jak działa robots.txt w praktyce?
Roboty wyszukiwarki skanującej stronę, kiedy trafią na plik robots.txt, otrzymują instrukcje odnośnie swoich dalszych działań na danej witrynie. Zazwyczaj są to zezwolenia lub zakazy wejścia we wskazane obszary strony. Bezwarunkowe ich zastosowanie nie jest jednak możliwe. Algorytm może wziąć takie zalecenie pod uwagę, ale nie ma takiego obowiązku. W przypadku Google algorytm zazwyczaj podąża wytyczoną ścieżką. Inne wyszukiwarki są w tym aspekcie mniej przewidywalne. Ignorujący instrukcję robot przeskanuje zatem wtedy również obszar witryny, który według naszych preferencji miał zostać pominięty.
Dlaczego stosowanie robots.txt jest ważne?
Istnieje wiele powodów stosowania opisywanej metody. Niewątpliwie plik robots.txt to istotny element zarządzania daną witryną. Wprawdzie nie jest obligatoryjny, ale jego użycie jest rekomendowane, bo może przynieść wiele korzyści dla strony internetowej oraz dla samych internautów. Właściciel witryny najczęściej decyduje się na wykorzystanie pliku, kiedy zależy mu na:
- zarządzaniu duplikacją treści – robots.txt pozwala administratorom zablokować obszary strony WWW, które zawierają dużą ilość wewnętrznie powielonej treści, w niektórych przypadkach może to wpływać na znaczące oszczędności transferu;
- bezpieczeństwie i ochronie prywatności – wybrane obszary witryny, np. wersje testowe albo robocze, nie powinny być publicznie dostępne, omawiany plik może to zapewnić blokując robotom dostęp do określonych sekcji i jednocześnie ograniczając je dla przypadkowych użytkowników, kontrola nad widocznością mediów i zasobów ma duże znaczenie np. w przypadku banków zdjęć – w wyszukiwarce prezentowane będą wyłącznie mniejsze wersje fotografii;
- ochronie przed przeciążeniem serwera – boty poszukujące danych do zaindeksowania są w stanie generować duże obciążenia, ograniczenie i kontrola ich ruchu to skuteczne działanie wspomagające na rzecz zapobiegania takim sytuacjom;
- optymalizacji budżetu indeksowania Google – roboty wyszukiwarki mają określony czas, jaki przypada na indeksowanie danej strony – określa go tzw. crawl budget, plik robots.txt może wpłynąć na to, aby algorytmy nie marnowały czasu na skanowanie mniej istotnej treści dla użytkowników Internetu, ale skupiły się na kluczowych elementach strony WWW.
Robots.txt a działania SEO
Duplicate content, czyli duplikacja treści sprawia, że podstrony w obrębie witryny się kanibalizują. To negatywnie wpływa na ich wiarygodność oraz pozycjonowanie w wyszukiwarce Google. Dzięki robots.txt można temu zapobiec. Na ranking strony WWW wpływa również odpowiednio wykorzystany crawl budget, zwłaszcza w przypadku bardziej rozbudowanych witryn. Dlatego tak istotne jest zwiększenie prawdopodobieństwa, aby boty wędrowały wyznaczonymi ścieżkami. Niektóre obszary strony są bowiem nieistotne dla SEO lub negatywnie oddziałujące na proces pozycjonowania, a inne odgrywają wręcz kluczową rolę. Odpowiednia konfiguracja robots.txt wpływa bezpośrednio również na szybsze wyniki. To zatem kolejny ważny aspekt pozycjonowania i planowania strategii optymalizacyjnej pod kątem wyszukiwarek internetowych.

Zawartość pliku robots.txt
To prosty plik, więc nie może zawierać zbyt wielu elementów. Umieszczone w pliku robots.txt krótkie i nieskomplikowane informacje tekstowe są zrozumiałe dla botów. Plik musi zawierać co najmniej jeden blok z regułą (dyrektywą) zezwalającą lub odmawiającą dostępu. Do tego dochodzą oznaczenia robotów, których dotyczą za pomocą identyfikatora user-agent. W ten sposób dyrektywy mogą być kierowane do wszystkich botów lub wybranych, np. Googlebot Desktop czy Googlebot Images. Jedyny dodatkowy element pliku, jaki może wystąpić, to link do mapy strony w formacie xml. Składnia robots.txt również jest nieskomplikowana. Wskazując wyszukiwarkę przypisuje się do niej regułę. Symbol gwiazdki (*) oznacza wszystkie boty z wyjątkiem AdsBot. Blokowanie wszystkich adresów URL kończących się danym ciągiem znaków dokonuje się za pomocą symbolu „$”, natomiast komentarze wprowadza się po symbolu „#” – wyszukiwarki nie biorą tych fragmentów pod uwagę, więc nie mają one wpływu na funkcjonalność, a jedynie na to, jak plik może ostatecznie wyglądać.
Przykładowy plik robots.txt w WordPressie ma następującą budowę:
Allow: /wp-content/uploads/
Disallow: /wp-content/plugins/
Disallow: /wp-admin/
Sitemap: https://example.com/sitemap_index.xml
Robots.txt – przykładowe reguły z przeznaczeniem dla algorytmów wyszukiwarek
Dyrektywy są istotą pliku tekstowego robots. Za ich pomocą można wpłynąć na konkretne działanie wyszukiwarek internetowych, które w domyśle mają pozwolenie na wertowanie wszystkich adresów URL. Z użyciem określonej formuły właściciel lub opiekun witryny ma możliwość blokady dla całej strony wszystkich robotów, sekcji, katalogu, pliku czy rozszerzenia. Sposób działania zależy więc od preferencji. Warto zaznaczyć, że przy większej liczbie dyrektyw kolejność ich wpisywania nie ma znaczenia. Są one traktowane równorzędnie. Reguły, które należy poznać, to przede wszystkim:
- Dyrektywa User-agent – określa boty, do jakich kierowana jest konkretna instrukcja postępowania, część z nich można tu wykluczyć;
- Dyrektywa Allow – polecenie zezwalające na dostęp, wskazuje obszar Twojej strony internetowej, gdzie algorytmy powinny mieć wgląd, z racji domyślnego pozwolenia zazwyczaj używana jest do tworzenia wyjątków w postaci konkretnej podstrony. Algorytm wyszukiwarki rozróżnia wielkość liter w wartości pola. Oczywiście w razie potrzeby można wycofać tę zgodę i ograniczyć dostęp do niektórych obszarów witryny;
- Dyrektywa Disallow – określa miejsca witryny, jakich robot wyszukiwarki nie powinien skanować. Wielkość liter jest rozróżniana przez robota. W tym przypadku Google nie może indeksować stron, ale ich adresy URL tak, choć będą one wyświetlane bez fragmentu treści. Reguła przydaje się, kiedy właściciel witryny nie chce wpuścić robota wyszukiwarki na podstrony z treściami poufnymi albo zawierającymi duplikaty treści. Bywa, że jest ona ignorowana – dlatego lepszym sposobem na wyłączenie strony z indeksowania jest dodanie w jej kodzie linijki:
-
<meta name=„robots” content=„noindex”>
-
- Dyrektywa Sitemap – opcjonalna reguła, którą warto stosować zwłaszcza w przypadku rozbudowanych i często aktualizowanych stron internetowych. Ułatwia wyszukiwarkom znalezienie oraz indeksowanie wszelkich zmian, a także zrozumienie struktury witryny. Wielkość liter jest tu rozróżniana;
- Dyrektywa Host – pozwala na wskazanie preferowanej domeny, kiedy w Internecie występują jej kopie. Roboty Google pominą jednak zastosowanie tej reguły;
- Dyrektywa Crawl delay – roboty różnych wyszukiwarek nieco inaczej interpretują tę dyrektywę, np. Googlebot ją zignoruje. Wskazuje ona czas, jaki musi upłynąć pomiędzy kolejnymi indeksowaniami strony internetowej, co ma sprawić, aby nie doszło do przeciążenia serwera, kiedy strona jest jednocześnie przeszukiwana przez kilka robotów. Dzięki tej dyrektywie częstotliwość skanowania jest bowiem mniejsza;
- Dyrektywa Clean-param – wygodna reguła pozwalająca ignorować szczegółowe i dynamiczne parametry, które są przypisane do adresów we wskazanych ścieżkach, ale nie wpływają na samą zawartość danego serwisu. Regułę tę obsługują pojedyncze i mniej znane wyszukiwarki;
Jak stworzyć plik tekstowy robots?
Do utworzenia pliku robots.txt najlepiej sprawdzi się edytor tekstu, który nie dodaje formatowania, np. Notepad lub TextEdit. Zapis z użyciem dyrektyw powinien być zwięzły i możliwie najprostszy. Następnie plik należy zapisać jako „robots.txt”. Kolejny etap to umieszczenie go w głównym katalogu strony, do której się odwołuje, aby był dostępny po dopisaniu jego nazwy po ukośniku do domeny. Jeśli konieczne jest określenie formy kodowania, należy wpisać UTF-8. W tym przypadku w składni powinny znajdować się wyłącznie znaki z kodu ASCII. Robots.txt można stworzyć również za pomocą strony internetowej (jako podstronę) lub z wykorzystaniem narzędzi do jego generowania, np. Screaming Frog SEO Spider czy Internet Marketing Ninjas Robots Text Generator. Edycja pliku wymaga zmian odnośnie zapisanych w nim dyrektyw. Reszta czynności przebiega analogicznie.
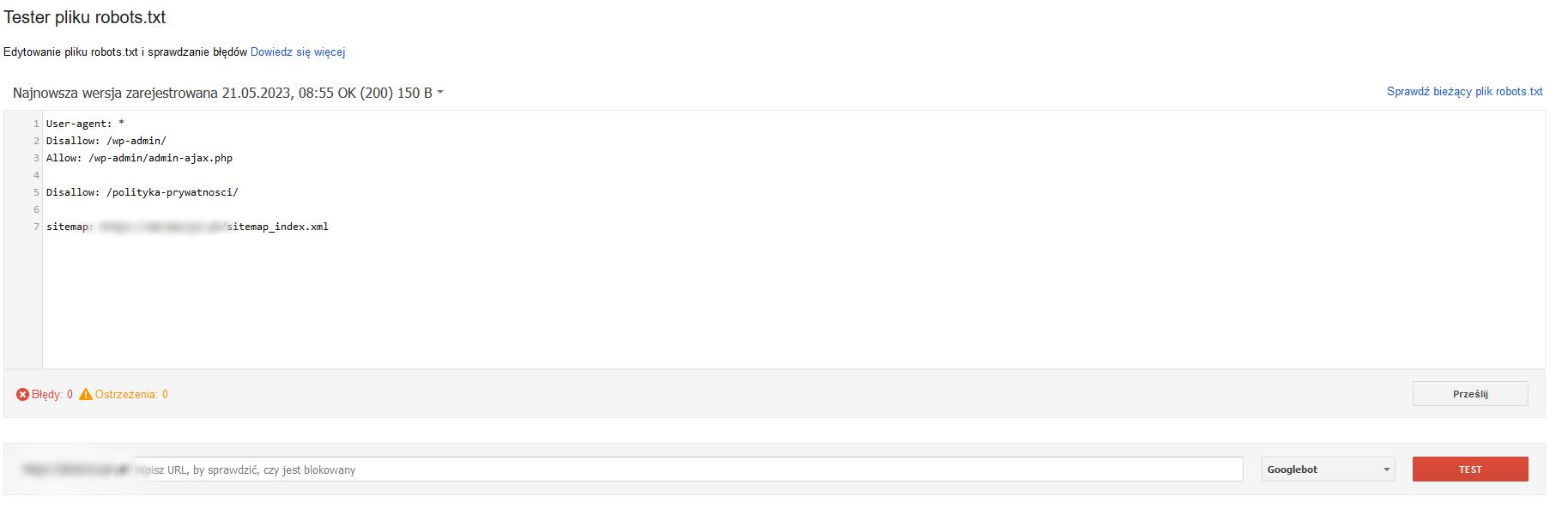
Testowanie pliku robots.txt i prawidłowości jego działania
Sprawdzenie prawidłowego funkcjonowania pliku to osobna czynność, której nie powinno się bagatelizować. Zwłaszcza w przypadku rozbudowanych serwisów, gdzie o pomyłkę nietrudno. Tym bardziej, że nie jest to zadanie szczególnie skomplikowane. Najpopularniejszym narzędziem, które wspomoże kontrolę jest Google Search Console. Należy wpisać swoją domenę, a w zakładce „Pobieranie” wskazać na opcję „Tester pliku robots.txt”. Dostępne dla robotów podstrony zostaną podświetlone na kolor zielony, a niedostępne na czerwony. Według tych zapisów funkcjonować będą również Googleboty, a więc te obsługujące najchętniej wykorzystywaną wyszukiwarkę na świecie. Po wprowadzeniu nawet najmniejszych aktualizacji w składni pliku powinno przetestować się go ponownie.
Najczęściej występujące błędy i problemy podczas tworzenia pliku robots.txt
Przy tworzeniu pliku, który ma zarządzać ruchem botów indeksujących konieczna jest bardzo dobra znajomość strony oraz reguł. Przy tym zawsze należy zapisywać je z dużą starannością oraz spokojem. Błędne ich zastosowanie może bowiem spowodować rezultat odwrotny od tego zamierzonego. Nawet drobne niedopatrzenie sprawi, że zamiast polepszenia pozycji strony w wyszukiwarce nastąpi jej znaczące pogorszenie. Do najczęstszych błędów i problemów przy tworzeniu pliku robots.txt należy zaliczyć:
- Niewłaściwą składnię – brakujące dwukropki po regułach i niepoprawne zastosowanie wieloznacznych symboli należą do powtarzających się niedopatrzeń u wielu użytkowników. Niestety to wystarczy, aby roboty indeksujące nie były w stanie odpowiednio zinterpretować dyrektyw.
- Niedostępność pliku robots.txt – jeżeli znajduje się on w niewłaściwej lokalizacji, nie jest w stanie zarządzać ruchem botów na naszej stronie internetowej. W związku z tym roboty indeksujące przeszukają pełne zasoby witryny.
- Blokadę ważnych podstron lub zasobów – w wyniku przypadku lub braku umiejętności można w łatwy sposób zablokować zasoby witryny istotne ze względu na jej pozycjonowanie. To błąd, który może nieść za sobą poważne konsekwencje i znaczące spadki w rankingu wyszukiwarek.
- Zbyt dużą liczbę dyrektyw – nadmiar reguł niesie za sobą ryzyko, że boty będą mieć problemy z właściwym odczytaniem skierowanych do nich instrukcji, a w konsekwencji z dostosowaniem się do ich zapisów.
Wskazówki, zalecenia i uwagi dla użytkowników
Podczas tworzenia dyrektyw w dokumencie tekstowym zaleca się używanie nowej linijki i bloku dla każdej z reguł. To sprawi, że będą one bardziej czytelne i przejrzyste dla botów indeksujących. Zmniejsza też ryzyko pomyłek i ułatwia zarządzanie plikiem. Z podobnych powodów dobrze, gdy każdy user-agent zostanie użyty jednokrotnie grupując wszystkie skierowane dla niego dyrektywy. Należy bezwzględnie pamiętać, że choć plik robots.txt może wskazywać ścieżkę dla robotów, to nie zabezpiecza on dostępu do zasobów. Dlatego nie jest to dobry pomysł na ochronę informacji poufnych. Na podstronę może wejść każda osoba wpisująca jej adres. Nadal może ona też pojawiać się w wynikach wyszukiwania, kiedy prowadzą do niej linki zewnętrzne.
Podsumowanie
W wyniku przypadku lub braku umiejętności można w łatwy sposób zablokować dostęp robotom do zasobów witryny. To błąd, który może nieść za sobą poważne konsekwencje i znaczące spadki w rankingu wyszukiwarek. Jednak nie należy się go obawiać – wystarczy zachować ostrożność. Plik robots.txt jest istotnym elementem optymalizacji strony pod kątem wyszukiwarek internetowych, w tym zwłaszcza tej najpopularniejszej od Google LLC. Prawidłowo zaplanowane reguły wpłyną na proces indeksacji. Sprawne zarządzanie ruchem botów na stronie wymaga jednak dużej wiedzy, umiejętności, ale też drobiazgowego podejścia do tematu. Drobna pomyłka zniweczy tutaj całą pracę. Dlatego tak ważne jest rzetelne testowanie pliku przed jego zastosowaniem. Jednocześnie należy pamiętać, że wyszukiwarki mogą pominąć skierowane w ich stronę zalecenia, bo nie są zobligowane do tego, aby je bezwzględnie wykonać. Mimo to i tak warto stosować element robots.txt, aby zwiększyć szanse na skuteczne pozycjonowanie strony internetowej. W rywalizacji o jak najlepszy ranking każdy drobny element ma znaczenie.
FAQ – najczęstsze pytania i wątpliwości dotyczące pliku robots.txt
Czy jest sens stosowania pliku robot.txt w sytuacji, gdy chcemy udostępnić wyszukiwarce całe zasoby strony internetowej?
Plik robots.txt na stronie internetowej nie jest koniecznością, ale jego zastosowanie niesie za sobą określone korzyści. W niektórych przypadkach zdecydowanie lepiej wykluczyć niektóre obszary z indeksowania, aby wspomóc optymalizację pod kątem SEO. Nawet jeśli właściciel witryny nie zamierza blokować robotom dostępu do żadnej z podstron, warto zastosować dyrektywę zezwalającą na to wszystkim wyszukiwarkom. Brak pliku może zostać bowiem zinterpretowany jako brak dbałości o stronę, a sama witryna uznana za mniej wartościową dla użytkownika Internetu.
Czy da się odgórnie wskazać typ podstron, jakich roboty nie powinny indeksować?
Niektóre podstrony zawierają treść, która nie jest istotna pod kątem wyników wyszukiwania. Mądre zarządzanie crawl budgetem wymaga ich wykluczenia z procesu indeksowania. Do tej grupy zaliczyć można: stronę logowania, panel użytkownika, wyszukiwarkę wewnętrzną, koszyk zakupowy, a także wszelkie informacje prawne i regulaminy – polityka prywatności, zasady składania zamówienia czy regulacje na temat przetwarzania Twoich danych osobowych. Oczywiście z indeksowania warto wyłączać również podstrony z duplikującą się treścią czy wersje testowe.
Ile potrzeba czasu, aby zaobserwować zmiany w wynikach wyszukiwania spowodowane zastosowaniem lub aktualizacją pliku robots.txt?
Google nie daje w tym temacie jednoznacznych odpowiedzi. Zazwyczaj na zmiany trzeba poczekać 1 dzień, ale w przypadku niektórych adresów URL może to potrwać dłużej. Wszystko zależy od tego, ile czasu zajmuje ich indeksowanie. Cały proces można jednak przyspieszyć przesyłając do Google plik robots.txt, który został zaktualizowany.
Dlaczego blokada stron z zastosowaniem robots.txt nie jest w pełni wystarczająca i jak ją w tej sytuacji zapewnić?
Plik robots.txt nie stanowi formy zabezpieczenia informacji i nie w tym celu został stworzony. Sugeruje on wyszukiwarkom pewne działanie, ale nie jest w stanie im go narzucić. Ponadto część wyszukiwarek, w dużej mierze tych mniej popularnych, nie dostosowuje się do poleceń zawartych w danym pliku. Zdarza się więc czasem, że robot nawet po odczytaniu zakazu wejdzie na podstronę, a następnie doda ją do indeksu pokazując wyłącznie jej tytuł i adres bez dodatkowych treści. Wystarczy to jednak, aby internauta przeszedł na nią z poziomu wyszukiwarki. Aby zablokować dostęp do danych znajdujących się na serwerze, należy stosować inne skuteczniejsze metody.
Czy zablokowanie strony z dyrektywą disallow ze wskazaniem wyszukiwarki Google sprawi, że dana strona zniknie z wyników wyszukiwania?
Jeśli została już zaindeksowana – to może nie wystarczyć. Należy skorzystać z sekcji „Usunięcia” w Google Search Console by poinformować Google o chęci wyindeksowania danej podstrony. Jeśli chcemy mieć pewność, że dany adres nie zostanie zaindeksowany (pierwszy raz lub ponownie) – warto dodać w kodzie strony <meta name=”robots” content=”noindex”>.





